Rule Tutorial
The previous tutorial introduced the Dialog API. This tutorial covers rule development in more detail. During the course of this tutorial you will see how the engine combines multiple NLP (Natural Language Processing) techniques in a single unified framework. We begin with the simplest approach, namely rewrite rules.
If you followed the previous tutorial, you will recall how we used the Dialog API's dashboard to add a first rule:
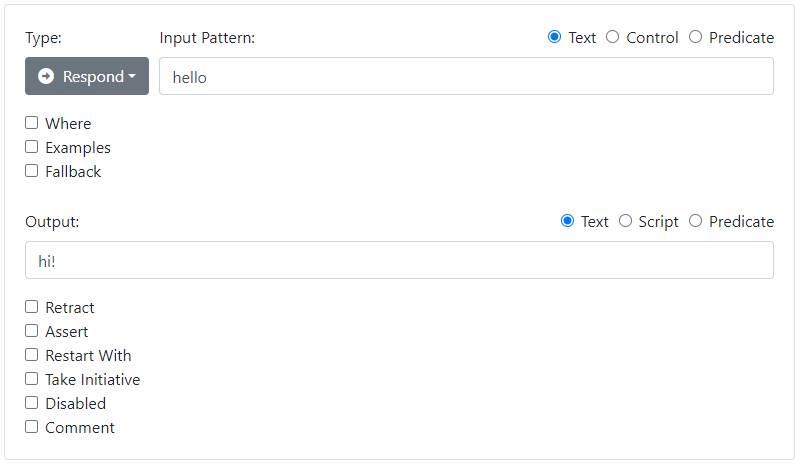
If you Export your model, you will get a JSON file that looks like this:
{
"items": [
{"id":100, "type":"respond", "textinput":"hello", "textoutput":"hi!"}
]
}
As you can see, other than the unique id, there is a simple correspondence between the UI and the JSON fields in the data file. In fact some users prefer to edit model files directly in a text editor, and there are API endpoints available for uploading and downloading a model in JSON form, to facilitate this. But working with the dashboard is definitely easier, so that's where we'll start.
In the Dialog API, we adopt an intermediate syntax for rules that makes the essential information evident. Here is that same rule according to our conventions:
-
hello → hi!
This syntax is shown in the dashboard and is also used extensively in this document.
Basic Text Patterns
The rule above is an example of a precise text match. The user has to type "hello" for the match to occur. Case or punctuation does not matter, so the string "Hello!" would also match. However the input "hello there" would not match. To match either input, you could use two rules:
-
hello → hi!
hello there → hi!
There are many techniques to manage the different ways people have of saying the same thing. One way is to use wildcards. The star character ('*') denotes zero or more words. So another way to model this is:
-
hello * → hi!
This model is said to overgenerate - it matches "hello my friend" but also "hello what can you do".
In addition to '*', you can use '+' to denote one or more words, and '_' to denote a single word. You can also use square brackets to denote optional text. So the "hello / hello there" phenomenon can more precisely be modeled with:-
hello [there] → hi!
In working with natural language, there is a tension between writing lots of precise rules, and writing fewer rules that overgenerate. There is a place for both approaches. One extreme case of overgeneration could be called "keyword spotting".
-
* dog * → I had a dog once.
You may be familiar with this simple pattern-response technique, as well as its limitations. The Dialog API starts with the idea of rewrite rules, but builds on this with a psychologically accurate model of the interpretation, response, and generation process.
The Conversational Arc
When you hear your friend speak to you, subconscious parts of your brain involved with acoustics and language are rapidly firing, exploring the possible meanings of what your friend might have said. They take into account acoustic models, the context of what was said just prior, as well as the situation that you are in, to predict what your friend is trying to communicate. At some point a coalition wins out: of all the possible interpretations, one is singled out as the most likely one, and we commit to it. This is when you become consciously "aware" that your friend has said anything at all. You are likely also immediately aware of how to respond, even though you might spend some time deliberating on the details of that intention. Finally the unconscious "language generation" portions of the brain take over as you determine how to translate that intention into words, and ultimately muscle movements for speech production.
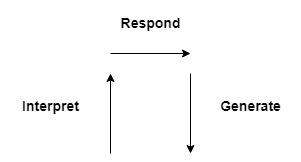
The Dialog API also uses the Conversational Arc to organize rules. Different types of rules, with different selection criteria, are involved in the Up, Right, and then Down portions of the arc.
- In the Up portion, Restate rules, shown with the icon , restate the input into simpler and more canonical forms
- In the Right portion, Response rules, shown with the icon , commit to an interpretation of the input, update the mental state, and determine a response
- In the Down portion, Generation rules, shown with the icon produce an actual text output that is appropriate.
In the previous section we had exactly one Response rule contribute to the entire arc, from interpretation, to response, and then to generation. In more sophisticated chat systems, several rules contribute to this arc.
Canonicalization
Many different words can mean the same thing. Let's improve the range of input we can deal with:
-
hello → hi!
hi → hi!
bonjour → hi!
or we can write these three rules as one with
-
(hello|hi|bonjour) → hi!
The vertical bar syntax within parentheses indicates that precisely one alternative can be chosen.
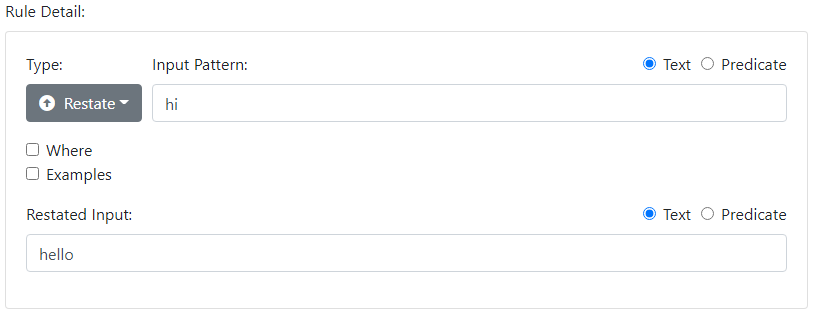
Another way to deal with the phenomenon is to pick one word, say "hello", as the "correct", or "canonical" representative of the word, and then transform, or restate the others as "hello".
-
hi → hello
bonjour → hello
hello → hi!
If the user says "hi" or "bonjour", a rule converts this "alternate" input to the "generic" input "hello". Then another rule completes the arc to produce an output. We called the "upward" rules "canonicalization", since they drive different inputs to a standard intermediate format.
The and icons help remind us of the location of the rules on the arc. For example, going from "bonjour" to "hi!" involves both a Restate rule and a Response rule. When editing in the dashboard, use the Type dropdown to indicate the rule type.
The Chart
Rewrite rules have traditionally been the workhorse of natural language processing. Early systems based on rewrite rules would work in a strictly sequential fashion, i.e. a single rewrite rule is chosen to fire, and then the intermediate output is considered, as if it were the new user input. This gets you into trouble if you add a rule that looks explicitly for "bonjour", such as:
-
hi → hello
bonjour → hello
hello → hi!
bonjour → salut!
In a sequential system, the last rule might never fire because "bonjour" would no longer exist as an input to be considered, being that it was transformed to "hello". Getting such a system to work correctly is difficult, and often relies on tweaking the rule order.
The Dialog API uses a data structure known as a "chart" that allows it to consider all Restate rules in parallel. Just because a Restate rule fires doesn't mean that it needs to contribute to the chosen interpretation. For the Dialog API, the above example just means that there are two Respond rules that can fire for the word "bonjour". Just like in our own minds, the system needs to commit to exactly one Respond rule. The way it does this depends on the situation, but the decision is deferred until all possible Restate rules have been attempted.
Removing Extraneous Input
Through canonicalization, we can use a rule to rewrite the "hello my friend" input as just "hello".
-
hello my friend → hello
-
* my friend → *
Here a '*' is used on the RHS (Right Hand Side) of the rule to represent the text that the * is standing in for on the LHS. So you can interpret this rule as stripping off "my friend" when it appears at the end of an input. An important part of driving towards a canonical input is removing the "fluff" that we tend to use to decorate our speech, while recognizing that this "fluff" can serve a secondary social purpose.
Substitute Rules
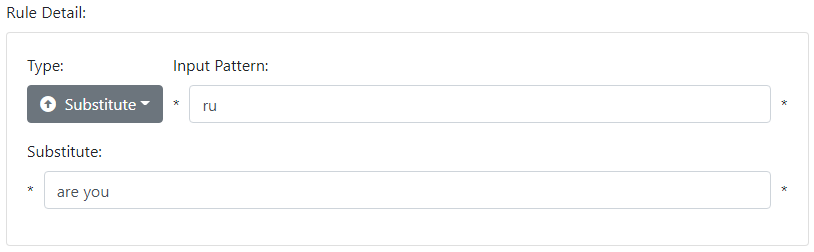
Note that Restate rules specify a pattern for the entire input. Substitute rules are just like Restate rules except they apply to a specific word or words. Substitute rules are often used to map abbreviations, shortcuts, or even misspellings, to their regular form, as in:
-
* ru * → * are you *
Substitute rules are equivalent to Restate rules, but they are simpler, and since there can be a lot of them, the engine handles them a bit differently. As a result, it is slightly more efficient to use Substitute rules if you are just replacing words and you don't care what comes before or after. Note how the '*' character is used to remind you that everything before and after the word is preserved.
Matching always occurs without case or punctuation. You may wonder about English contractions, as in "can't", short for "can not". As part of canonicalization, we normally remove contractions using Substitute rules such as:
-
* can't * → * can not *
Note that the same case and special character treatment is applied to the LHS of rules, prior to the match: all letters are converted to lower case, and all non-letters are converted to a single space. This means you can use a punctuation mark in your pattern, as we did in the above example.
The Dialog API's rule editor will try to guide you towards using the more canonical form. For example, in the presence of the previous rule, if you create a response rule with "can't" as an Input Pattern, you may see the following recommendation:

This makes sense - if you have rules that are driving the input to a more canonical form, then you want a Response rule to use that canonical form as its pattern, in order to capture as many variations of the input as possible.
Restate and Substitution rules have an extra "Greedy" checkbox. Normally the Dialog API is very careful to consider both a world in which a given rule is used, and a world in which it isn't. In other words each transformation is tentative - it may or may not contribute to the final arc. This normally works well, but there are times when you always want a transformation to occur. You can tell the engine about this using the Greedy checkbox, which will allow it to "greedily" apply the rule whenever it can and never consider the alternative world in which the rule does not apply. This can lead to performance improvements, as it rapidly shuts off entire avenues of exploration. The Greedy checkbox is meant as an advanced feature, and can be left off for most rules.
Restarts
We talked about how a given input results in a commitment to a certain output. Normally that output is sent directly to the user. But there are times when it is convenient to chain two or more cycles of the engine together. The first rule may even contribute something to the output, but then we respond again, AS IF the user said something else.
We saw how canonicalization can lead us to ignore nuances in the formulation of a question. But you might acknowledge a polite formulation in one sentence, and then proceed to answer the basic question in the next using a restart.
-
> what is your Name
My name is Michelle.
> could you please tell me your name
Of course. My name is Michelle.
You could do this with:
-
(what is | tell me) your name → My name is Michelle.
could you please * → Of course. [restart *]
It's important to remember that a Restart occurs after the first Respond has been committed-to and an output has been created, even if that output is blank.
There are actually two complete iterations of the conversational arc, however they will appear as one input/output pair in the history.
Predicates
The Dialog API lets you use predicates and predicate unification for internal representations of meaning, facts about the user, and more. You may be familiar with these concepts from the Prolog or LISP programming languages. They are a precise, mathematical tool for encoding meaning, or semantics. Predicates are optional for simple rule systems, but are very useful as your chatbot grows in complexity. Let's look at some examples.
-
Loves(John,Mary)
The expression above is an example of a relationship Loves that applies between John and Mary. You would read it as "John loves Mary". John and Mary are also predicates - rather than expressing a two-way relationship, they simply represent known entities. (Spaces are normally omitted from predicates and predicate expressions in the Dialog API.)
Predicates with a single argument are normally used to represent ontological, or "is a" information. For example
-
Person(John)
is normally read "John is a Person".
Predicates with two arguments can be used to represent relationships or properties.
-
Age(John,35)
The values John, Loves, Person, Age are just symbols, but they acquire meaning when they are used in a consistent manner. Importantly, predicates are language-independent. For example you could use predicates to translate between French and Spanish - the fact that these symbols use English words has relevance only to the rule author. In fact the choice of what symbols you use for your predicates is ultimately up to you. That said, there are certain conventions that are highly recommended, if for no other reason that there are examples, stock models, and a developer community that use them.
One such convention is to "ground" predicates in the terminals Agent, for the chatbot, and User, for the user. So facts about a user might be stored as follows:
-
Age(User,35)
Symbols like User and Agent can be thought of as "proper names", i.e. they last forever and provide an unambiguous anchor that we can layer other facts onto. But most entities in natural language are more ephemeral - they are are introduced as needed by the speaker to refer to things, and it is up to the listener to "bind" them to something based on the context. For example the phrase "my dog" might be represented as
-
Dog(d1)^Possessor(d1,User)
Here the '^' symbol is read as "and", and you might read it as "d1 is a dog, and the possessor of d1 is User". We normally use short, lower-case, numbered symbols like 'd1' to represent such ephemeral entities - we call them instances.
Rules will often refer to the actual text inputs and outputs of the system, so these too are entities - instances of communication, if you will. By convention, all inputs are labeled with the letter i' in the order in which they occur, i.e. i1, i2, i3, etc. Likewise all outputs are labeled o1, o2, o3. Furthermore, the current input being processed by a rule is known simply as i, and the current output being processed by a rule is known as o. A rule can refer to a previous input as i-1.
A final concept around predicates is the use of variables, or unifiers. These are short, lower-case variables beginning with '?'. Think of them as being able to take on the values of one (or more) entities. With variables, you can create queries. For example, you might ask:
-
Loves(John,?p)
i.e. "who does John love?" (answer ?p=Mary), or
-
Age(John,?x)
i.e. "what is John's age?" (answer ?x=35).
This may all seem like a lot at first, but remember that predicates are optional, at least for simple bots, and you can ease into using them when appropriate. So let's try that now.
Predicates as Canonical Form
The conventions introduced in the previous section open the door for Restate rules to restate inputs into predicate form. For example
-
(hello|hi|bonjour) → GreetingInput(i)
converts "hello" and variants to a canonical predicate form.
Here i refers to the current input, which is an instance of communication, and specifically of an Input. As a matter of style, we often use a multi-word predicate in which the final word reminds us of the class, or "type", of thing that it represents. In this case GreetingInput(i) reminds us that i is an instance of an Input - specifically a Greeting Input.
Note the radio buttons in the dashboard UI specify the output of the rule as being of type Predicate:
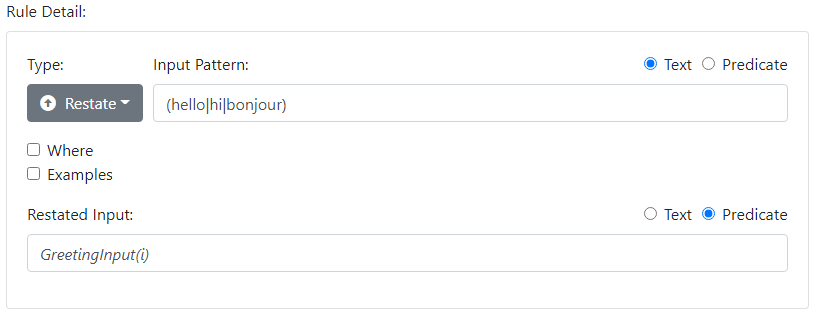
You can now have Respond rules that take a predicate form as input:
-
GreetingInput(i) → hi!
In this case we matched the predicate input directly to a text output.
Generation
You may have been wondering about the output, or generation side of the conversational arc. With the introduction of predicates, you can keep your response rules entirely in the form of predicates, if you choose.
-
(hello|hi|bonjour) → GreetingInput(i)
GreetingInput(i) → GreetingOutput(o)
GreetingOutput(o) → (hi! | hello!)
The first rule transforms the input to predicate form, the second one maps from an input predicate to an output predicate, and the third one translates the output predicate back to a text output. Notice that the '|' symbol is used to pick between two alternate outputs. The system automatically alternates between the available choices in order to avoid repetition.
You could also have used two different output rules:
-
GreetingOutput(o) → hi!
GreetingOutput(o) → hello!
Again, alternatives are used for variation. Note that the choice is not random. When different outputs are possible, the first one that is encountered in the rule file is used first. So if you have two outputs, and one is more verbose, you should consider putting it first.
If you use predicates that describe inputs and outputs, then the Model Tester will show them in the History panel, aligned with the lines they describe, rather than the World panel:
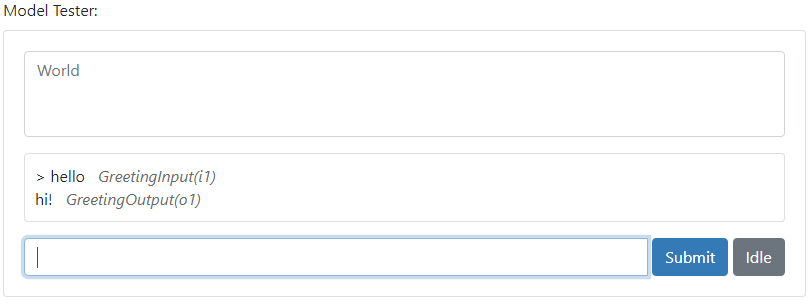
Conversation State
Predicates are used to store and retrieve information from the "conversation state". The conversation state is a package of information that tracks the conversation between the agent and a particular user. It includes the recent inputs and outputs, but it can also store things the agent has learned about the user. This state is often called the World. Consider this rule:
-
my name is * → hi * [assert Name(User,?capture)]
The rule is said to have the side-effect of asserting a new fact into the World. You would record this rule as follows in the dashboard UI:
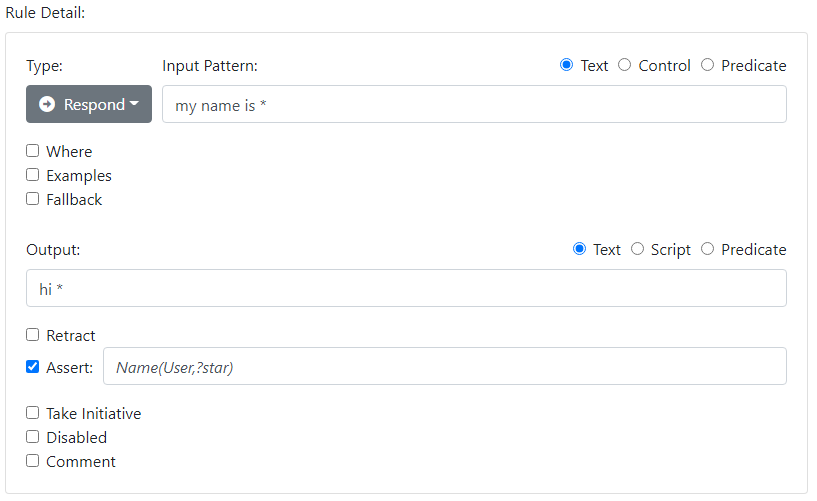
If you test this rule, you will see that a new fact will be added to the World:
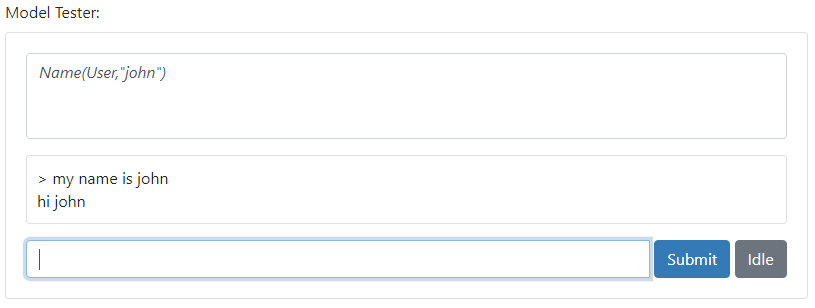
Note that Assert just adds a fact to the World. So after the exchange
-
> my name is john
> my name is jack
your World would contain two facts:
-
Name(User,"john")^Name(User,"jack")
to prevent this, you need to alter your rule as follows:
-
my name is * → hi * [retract Name(User,?x)] [assert Name(User,?capture)]
This way the system will remove all facts of the form Name(User,<anything>) prior to asserting Name(User,"jack").
Conditional Rules with "Where"
Rules will often have "Where" expressions that indicate whether they apply, and if so, allow for further information to be gathered for use in the output.
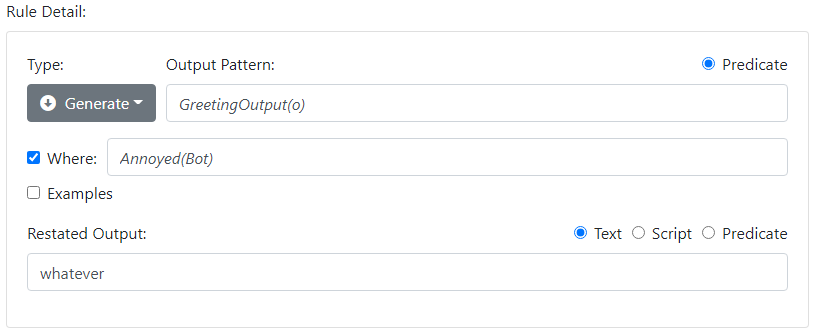
For example you might have two generation rules, and you might select between them based on the agent's mood. You might have a simple model of mood based on the presence or absence of the World predicate Annoyed(Agent), which you might have asserted at some point as a side-effect of a previous rule.
-
GreetingOutput(o) [where !Annoyed(Agent)] → hi!
GreetingOutput(o) [where Annoyed(Agent)] → whatever
You can use the Where checkbox to fill in the Where expression:
The ! operator means "not", so !Annoyed(Agent) is read "not annoyed agent" and is true if there is no fact Annoyed(Agent) in the World. Note that, in addition to displaying the contents of the World, the Model Tester also lets you edit the World directly. This is useful if you want to quickly test both outputs. To test the second variation you could manually add Annoyed(Agent) to the World and repeat your input.
You can use predicate unification on existing facts. For instance, let's say you used our earlier rule to record the user's name. You could access this information whenever you like, using a Where statement. The rule is enabled if there is at least one combination of unifier values that satisfies the Where expression. If this is the case, then the value (or values) of that unifier become available for insertion in the output:
-
who am I [where Name(User,?n)] → I know you as {?n}
who am I [where !Name(User,?n)] → I don't know your name
You might wonder what happens if there are two facts that unify with Name(User,?n), e.g. ?n="john","fred". When forced to an output with {?n}, the system will pick the first value found.
Built-in Predicates
As in many chat systems, the Dialog API removes all case and punctuation at the outset, which is why even if you typed "my name is John", the system would still have stored Name(User,"john"). To correct this, you could use a built-in predicate. These predicates are a bit like facts except that they act as functions. They are equivalent to built-in functions in Prolog. For example the built-in predicate Capitalize("john","John") is true whenever the second argument is a capitalized version of the first. Use it with a unifier to get a new value, so Capitalize("john",?x) is true, with the binding ?x="John" being established as a side-effect. We can use this in our Where expression as:
-
who am I [where Name(User,?n)^Capitalize(?n,?m)] → I know you as {?m}
This rule will still fail if there are no possible values for ?n, but if there is a value, then ?m will be guaranteed to be the capitalized form of that value. You could also have used this trick prior to asserting the Name fact in the first place.
Constant Facts
The Where mechanism is great for sharing information between rules. For example you might need to refer to the name of your chatbot in multiple rules:
-
what is your name → my name is Dave
who are you → I am Dave
Instead of repeating "Dave" in each rule, you can use the Add Facts button to create a Facts item:
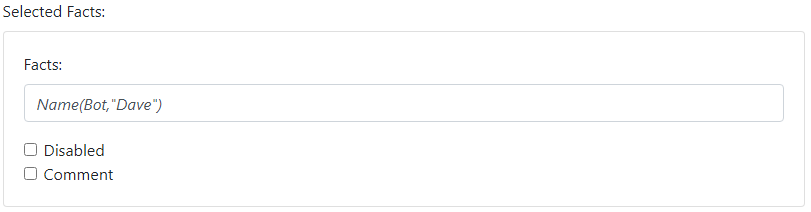
You can then rewrite your rules as:
-
what is your name [where Name(Agent,?x)] → my name is {?x}
who are you [where Name(Agent,?x)] → I am {?x}
You can use a Facts item to specify several facts by chaining them together with the AND operator '^'.
-
Name(Agent,"Dave")^Gender(Agent,Male)
Now you can also have a rule such as:
-
are you male [where Gender(Agent,Male)] → Yes I am.
are you male [where Gender(Agent,Female)] → No I am female.
This technique allows you to keep your rules as generic as possible, so that they can be reused from application to application. Facts specified in this manner do not live in the World, and cannot be altered using Retract. They represent permanent knowledge that cannot be changed except by updating the model.
Lexicon Rules
We have seen how we can use a Restate rule to convert a word input into a predicate expression:
-
(hello|hi|bonjour) → GreetingInput(i)
This works well for idiomatic phrases, but what if your input contains an "open class" noun, such as "New York" in "What is the weather in New York". In Natural Language systems we often refer to "New York" as an "entity". Ideally the same weather rule should apply to a whole class of entities, including "Houston", "Los Angeles", etc.
Lexicon rules let you add new entities, like "New York" to the system, and then map them to a specific predicate. For example we can say that:
-
* New York * → * N(SEM NewYork) *
The stars on either side of the input and the output remind us that this transformation applies to isolated words, and not to an entire phrase.
From linguistics, we know that most words belong to a few broad classes, namely Nouns, Verbs, Adjectives, and Adverbs. These classes are called Parts-of-Speech, and are normally given the shorthand symbols N, V, ADJ, and ADV. In this case, New York is a noun, i.e. an N. (It is technically a compound noun.) The parentheses after the N describe attributes of this particular N instance. In this case there is one attribute, the SEM, which is short for the Semantic, and it represents the predicate that corresponds to this noun.
Here is what our Lexicon rule looks like so far in the dashboard:

With at least one Lexicon entry, we can now return to our weather rule.
-
what is the weather in N(SEM ?x) → WeatherQuery(i)^City(i,?x)
But this is not enough. What is to prevent this rule from firing with the input "what is the weather in cat" if you had an entry for "cat" in the lexicon?
Words, and especially nouns, can be placed in an ontology using IsA facts. For example a "cat" is a "mammal", which is an "animal". On the other hand, "houston" is a "city", which is a "location". In predicate form we write this as an IsA fact:
-
IsA(NewYork,City)
We read this as "New York is a City'. You can add facts directly to a Lexicon rule using the Related Facts field:

This is equivalent to adding them in a Facts section - just more convenient.
Note that IsA predicate is one of the few predicates that are built-in. It is special in that it is transitive. That is, if
-
IsA(Cat,Mammal)^IsA(Mammal,Animal)
then
-
IsA(Cat,Animal)
will also be true.
We can now improve our weather rule by making it specific to city nouns:
-
what is the weather in N(SEM ?x) [where IsA(?x,City)] → WeatherQuery(i)^City(i,?x)
Note that you can also have multiple lexicon entries in which the same word maps to both a N and a V, or to two instances of N with different SEMs. All possibilities are examined as part of the search for the interpretation that the system will commit to.
Generation using Lexicon Rules
You can include other facts in the Lexicon rule. You might include a country for example.
-
IsA(NewYork,City)^Country(NewYork,UnitedStates)
This would allow you to use the following rule:
-
what country is N(SEM ?x) in [where IsA(?x,City)^Country(?x,?y)] → {?y}.
Note that the value ?y is a predicate, and yet we are inserting it into the text output! This is because Lexicon rules also work in reverse, for generation. That is they can translate a predicate back to a word. So provided you also had a lexicon rule
-
* United States * → * N(SEM UnitedStates) *
then you could have the following conversation:
-
> what country is new york in?
United States
If there are two ways to refer to the entity UnitedStates then you could use two Lexicon rules:
-
* United States * → * N(SEM UnitedStates) *
* USA * → * N(SEM UnitedStates) *
Or you can simply use the | operator:
-
* (United States|USA) * → * N(SEM UnitedStates) *
But when multiple lexicon entries are available for generation, only the first entry will be chosen, so the first entry is the preferred way of expressing the predicate.
We'll return to this type of rule when we introduce WordNet, which is a stock model that you can add to your Mind that provides a broad-based English dictionary of words and associated predicates.
Initiatives
Traditional chat systems tend to match every input to an output in a reflexive manner. But in real life conversation, we may listen to several inputs, perhaps offering just a nod or other acknowledgement, before responding with an output. And when we do, we might simply acknowledge what was said with a simple response, but then go on with something else. After all, we may have our own agenda for the conversation. Initiative rules are used to model this. An Initiative is a rule with an output but no input. Use it to describe something that the Agent might say. Consider:
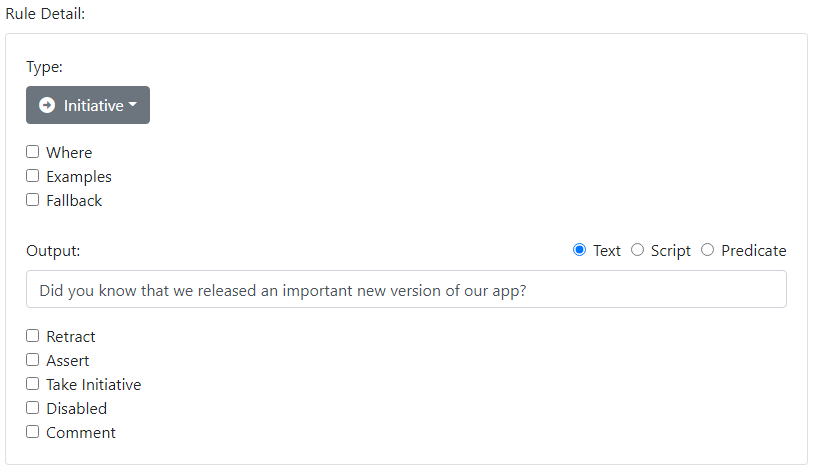
In text form we show this with the special word "initiative":
-
initiative → Did you know that we released an important new version of our app?
Initiative rules sit around waiting until another rules calls for an Initiative.
Just like someone you may know, a agent can be a poor listener but a good talker:
-
* → That's nice. [take initiative]
You would realize the output as follows in the UI:
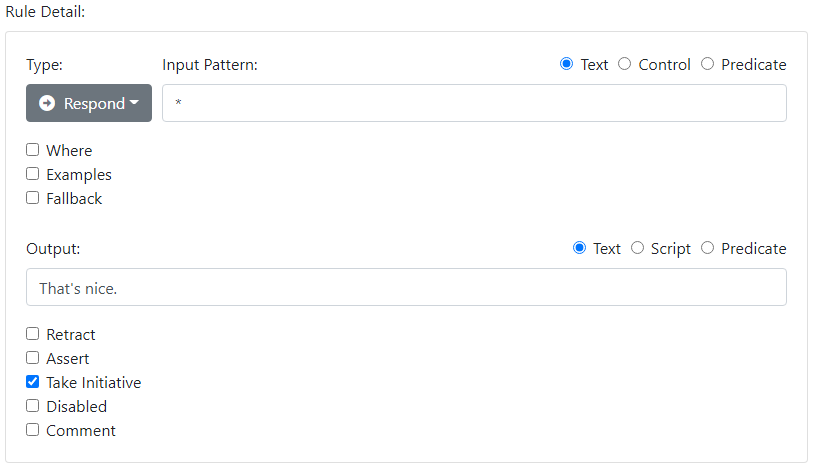
With this rule, your agent might hold the following conversation:
-
> I'm John.
That's nice. Did you know that we released an important new version of our app?
Note how the initiative follows the rule's regular output, if any is specified.
Initiatives are selected for repetition avoidance. They work a bit like variations in the output, e.g. (hi! | hello!), however unlike with output variations, a agent would rather not say anything (i.e. offer an empty output) rather than repeat an initiative. So in the absence of other Initiative rules, the conversation might continue as:
-
> I'm John.
That's nice. Did you know that we released an important new version of our app?
> Ok
That's nice.
Initiatives are often guarded by a Where clause. For example when casting about for something to say, a Agent can realize that they don't know the user's name, and decide to prompt them.
-
initiative [where !Name(User,?x)] → By the way, you didn't tell me your name.
Initiative rules are selected in the order that they are specified within a model. In practice, for larger bots with many models, you will often use a World predicate like Topic() that serves to focus the initiatives on a certain topic.
-
initiative [where Topic(Sports)] → How about those Buccaneers?
Predicates like Topic() can also be use to limit Respond rules to fire only in certain contexts and not others.
Idle
A related feature to Initiative is that of Idle. Chatbots can respond automatically, after a specified delay, using an Idle rule.
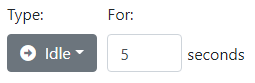
An Idle rule fires whenever a pause in the conversation occurs for a specified amount of time. It is common to have just one Idle rule, and its action is Take Initiative.
Control Inputs
The previous tutorial described some of the standard "control inputs" used in chat systems. These are non-verbal inputs, and typically come from other software rather than directly from the user, however you respond to them using all the same types of rules as for regular user input. In log files, control inputs always appear in square brackets. For example a [new] input is normally sent as soon as the chat UI becomes available to the user, and this allows the agent to make an opening statement. Similarly, the [return n] input is used to indicate that a known user has returned, where n represents the number of minutes of absence, and can be used to create a suitable return greeting. Another use for control inputs is to indicate user actions, such as [yes] or [no], resulting from buttons that are provided to the user as part of a previous output. Since control inputs come directly from software, they tend to be more precise and therefore easier to process. To respond to a control input, the Input type radio button should be set to Control. Square brackets appear reminding you that you are matching against a control input:
Because the input is precise, Restate and Substitute rules are not run, since there is no need to canonicalize them. Furthermore, if you pass parameters within the control command, then regular expression rules are used to extract them. For example, the command [return 60] could be parsed with the input pattern
-
return ([0-9]+)
Script Output
You can normally select between Text output or Script output. A Script is a series of one or more utterance, such as a sentence, in which each utterance is annotated with an action that describes how it is realized with an embodied agent.

This is simply a more discoverable way of specifying the following text output, which is equivalent:

In this case the material in square brackets is a "tag" that is effectively an instruction to other software, on the output side. Tags are typically used to influence text-to-speech systems, or to provide action cues to an embodied agent. The options shown in the Script UI correspond to the high-level tags employed by the Media Semantics Character API.
Wildcards and Fallbacks
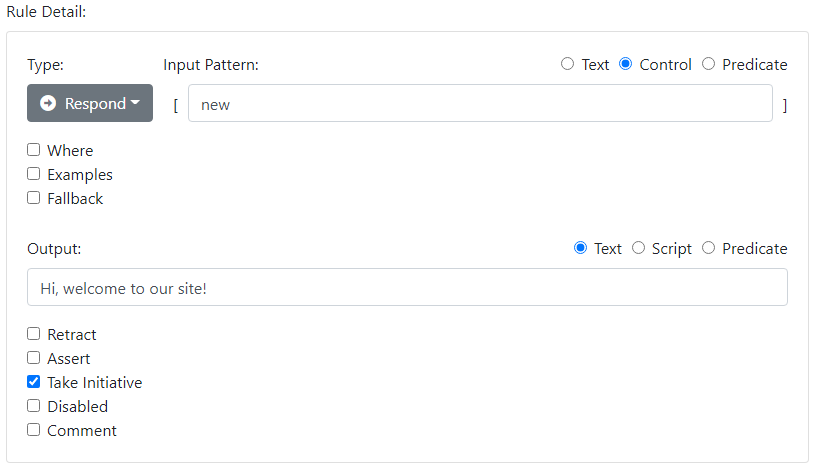
We saw already how the input pattern * can be used to match any input. This is therefore a very powerful rule, and you would typically constrain it using Where. It is not uncommon to have one strategy for precise dialog in some narrow domain, and a very different one when the precise rules fail to understand the input. To support such a dual strategy, rules can be marked with the Fallback checkmark. Fallback rules are completely ignored for the regular analysis. If, however, there are no Response rules that can fire, the system falls back to looking only at the Fallback rules.
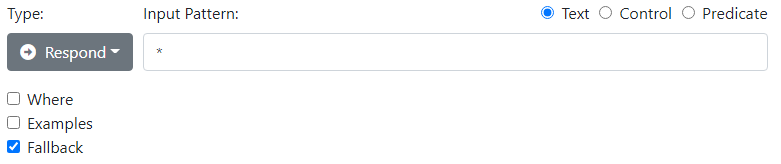
You might use keyword matching to identify that a give input belongs to a certain domain, even if you don't have rules to break it down precisely, and respond appropriately.
Using Dialog Context
We saw how "where" expressions can be used to guard rules based on predicates in the World. For example you might guard an initiative to ask for the user's name with "where !Name(User,?x)", i.e. "where we don't know the user's name". Consider how, in dialog, an input such as "yes" is only meaningful in the context of the question that came before it.
-
Can I tell you more about our products?
> yes
We also saw how the instance variable o represents the current output and i represents the current input. You can access the complete chat history using the syntax o-1, i-1, o-2, i-2, and so on. You can use the special predicate Contains(a,b) to probe the history. For example you could write a rule to handle the above situation as follows:
-
yes [where Contains(o-1,"can I tell you more about our products")] → Okay...
There is a more elegant way to do this, but only if you are keeping your respond rules at the predicate level. For example the rule that lead to the prompt above might be:
-
initiative → ProductPresentationPrompt(o)
ProductPresentationPrompt(o) → Can I tell you more about our products?
Now you can write your dialog rule more naturally as:
-
yes [where ProductPresentationPrompt(o-1)] → Okay...
Even if you're not ready to adopt predicates at a deep level, you can still use a "predicate annotation" on a text-based respond rule:
-
initiative → Can I tell you more about our products? [assert ProductPresentationPrompt(o)]
You might find it easier to use this approach, and simply tag certain outputs that you want to easily test for in subsequent dialog rules.
The Restart mechanism can be helpful for dealing with a short user input that can only be understood in context. Consider that we may already have a rule such as:
-
tell me about your products → We have two products...
Now we could use:
-
yes [where ProductPresentationPrompt(o-1)] → Okay. [restart "tell me about your products"]
This effectively converts a short answer to a question into a command.
Logical Form
We saw how inputs and outputs can be represented as distinct predicates, such as ProductPresentationPrompt(o). You can tag an input or output with several predicates joined by '^', and this can lead to some powerful generalizations. For example a previous rule could have been expressed as:
-
initiative → Can I tell you more about our products? [assert PromptOutput(o)^Theme(o,ProductPresentation)]
You might read this as "there is a PromptOutput o and the theme of o is a ProductPresentation."
In practice, natural language is often described by predicate expressions that introduce entities of a given type using predicates with one argument, such as PromptOutput(o), and then proceed to establish relations between these entities using predicates with two arguments, such as Theme(o,ProductPresentation). The entities themselves will vary widely from system to system and even from model to model, but only a handful of distinct relations, such as Theme, are normally used. In linguistics, we call these predicate expressions the "logical form" representation of the input.
A significant literature has been developed around logical forms, and how to use them to encode arbitrary human communication. Some approaches to natural language understanding begin with a complete "parse" of the user's input into a precise logical form. However this does not seem to be how our minds work, and such systems end up being very brittle. While there are grammatical and semantic patterns that emerge in language, they tend to be messy and riddled with exceptions. Nevertheless, word patterns do matter, and precise, logical-form like representations of key portions of the input are helpful in practical systems.
Anaphora
Another reason for using lexicon rules to tag entities is that it provides you with some powerful tools for dealing with anaphora. Consider the following exchange:
-
ACME's main product is the rocket sled.
> what's that?
Let me tell you more about the Rocket Sled...
Assume that you have created lexicon entries for all of ACMEs products, like so:
-
* rocket sled * → * N(SEM RocketSled) * [related facts: IsA(RocketSled,Product)]
You can then use the special predicate Entity(o-1,?x) to pick up the entities in the last output. This would let you create the rule:
-
what is that [where Entity(o-1,?x)^IsA(?x,Product)] → AboutOutput(o)^Theme(o,?x)
You can then create generation rules for each product such as:
-
AboutOutput(o)^Theme(o,RocketSled) → Let me tell you more about the Rocket Sled...
You can use Entity(o-1,?x) in the Query panel of the Model Tester to peer into previous inputs or outputs. A given sentence may have more than one tagged entity, so there may be more than one possible value for ?x. You can use "where" tests to further constrain this set, as we did with IsA(?x,Product). Ultimately, whenever a response is selected, the system will commit to a single set of bindings, and this would normally be the first set of values listed in the Query panel. Because Entity is used a lot with anaphora, it always lists its results in the reverse order of that in which entities were found in the input. So if you mention two products in the last output, then the last one mentioned will be favored by our anaphora rule.
LLMs and GPT Integration
Generative Pre-trained Transformers (GPTs) are LLMs that produce statistically-likely output given general world knowledge and the specific instructions and context that you provide.
The Dialog API does not include a GPT system directly. As with all external systems, communication with GPT occurs using tags. The API provides explicit support for the [gpt] tag, which is used by convention to communicate with the GPT subsystem, if present. The body of this tag is the prompt that is sent to GPT. The actual output of the Dialog API might look like this:
-
[gpt poem cat]
Before it reaches the user however, the tag is replaced with the actual result from the GPT subsystem.
The Dialog API provides support for building [gpt] tags. When used in the output of a rule, the tag has three parts:
-
[gpt name body]
The 'name' is the name of the Prompt rule to use. A Prompt rule is essentially a named template that is used to create the actual prompt text. Prompt rules let you maintain carefully-crafted text for your prompts in one place, and then simply call these templates by name where they are needed. The 'body' portion is optional. If present, you can use the special value {body} to insert the body portion of the gpt tag.
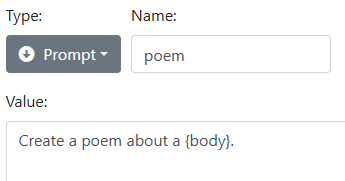
As a rule developer, there are many ways to use a GPT subsystem. As a text generator, GPT is particularly useful on the output side of the arc. You can use it to transform text to a different style, or a different language, or you can use it as a powerful creative tool.
-
create a poem about a * → [gpt poem {?capture}]
prompt poem: Create a poem about a {body}.
Auto Rewrite
One particular "tell" of a rule-based system is that it will repeat itself exactly for the same input. We have seen ways to mitigate this by using variations in the output with the (a | b) syntax, to provide an alternate (and often shorter) response the second time the same output is needed.
Here is another way:
-
input → (output | [gpt rewrite output])
prompt rewrite: Restate the following text: {body}
This is essentially what the Auto Rewrite feature does. This feature can be turned on in the Mind panel:

With Auto Rewrite turned on, all repetitive outputs are automatically rewritten using the 'rewrite' prompt, if specified, and there is no need to explicitly request it using the construction above. The first response received by the user is always the authored response. It is only if he or she persists with the same input that a GPT is used to generate variations.
External Tools and Streaming
A guiding principle with Dialog API development is to use a fast and inexpensive system to take the first crack at ALL user input. Usually this analysis results in a commitment to a certain interpretation and an output, even if that output itself may take more time to fully realize.
For example, a query about the weather can result in a commitment to query a subsystem for the current weather, using a tag such as [lookup-weather]. This tag is interpreted by the caller, and might result in a Web API query. When the answer comes back, a control tag is returned directly to the Dialog API as another input, where it can then be transformed by another rule to create the actual output. This "internal dialog" can be modeled and locked-down with tests within the Dialog API dashboard even before the external subsystems become available.-
what is the weather in N(SEM City) → Right. [get-weather {?capture}]
[return-weather (.*), (.*), (.*)] → The weather in {?capture1} is {?capture2} and {?capture3} degrees.
For simplicity, we placed the return values directly as parameters in the control input. Recall that control inputs use the more precise Regular Expression syntax on the pattern side.
-
> What is the weather in Seattle?
Right. [lookup-weather Seattle]
> [return-weather Seattle, rainy, 32]
The weather in Seattle is rainy and 32 degrees.
But note that the first weather rule is also structured to serve another function. Its output consists of two parts. The first part, "Right.", is available immediately, whereas the second part, [lookup-weather ...], might take some additional processing. By splitting it into sentences, the resulting output can be streamed, that is the "Right." portion can be displayed or spoken to the user even as the remaining text is being assembled. By rapidly committing to an interpretation, we can signal to the user that we understand, even as we pause to put together a complete answer. This type of latency management can be essential in conversational systems to avoid unnatural gaps in the dialog.
The effective output, as seen by the user is:
-
> What is the weather in Seattle?
Right. (short pause) The weather in Seattle is rainy and 32 degrees.
Payloads
In the previous section we saw how a lot of machine-to-machine communication happens through input and output tags in square brackets. But instead of placing arguments within tags, many developers prefer to use Payloads. Think of a payload as a fragment of JSON that travels along with a tag. You can use the Payload section in the output of a rule to elaborate on an outgoing payload. You can even drop in unifier values from a Where clause as you would with regular output.

When working with the dashboard's tester, you can also enter a JSON payload immediately after a text input containing a tag. Typically this is done to simulate a response from an outside system, for the purpose of building tests. JSON payloads appear interleaved in the history pane, and can also be copied to the transcript area of a Test in the same format.
-
> What is the weather in Seattle?
Right. [get-weather]
{
-
city: "Seattle"
> [return-weather]
{
-
schema: "WeatherRecord",
city: "Seattle",
weather: "rainy",
high: 32
The weather in Seattle is rainy and 32 degrees.
You can also access the contents of an input payload using rules in a Where clause with the special predicate Payload(). Incoming payloads can be marked using a named schema, as shown in the example above. Here you would add a schema item with the name WeatherRecord to any model in the mind. Schemas are declared in JSON using a format similar to JSON Schema, but with the addition of entity and relationship annotations. With the appropriate schema declaration, you can use a rule such as:
-
[return-weather] where Payload(i,?p)^City(?p,?c)^Weather(?p,?w)^High(?p,?h) → The weather in {?c} is {?w} and {?h} degrees.
Compare this to the previous version of this rule, in which arguments were passed directly in the tag:
-
[return-weather (.*), (.*), (.*)] → The weather in {?capture1} is {?capture2} and {?capture3} degrees.
The Payload and Schema capabilities are useful for exchanging non-trivial amounts of information, such as with external data sources and with interactive media running on the user's device. For example a user interface can pass in a [visual-context] tag with a payload that describes what a user is looking at. A rule such as:
-
[visual-context] where Payload(i,?p) → [retract Sees(User,?x)] [assert Sees(User,?p)]
can store this information in a manner that can then easily be queried in the Where clause of subsequent rules.
Retrieval
It turns out that LLMs are very good at summarizing text and extracting answers from it. In Retrieval Augmented Generation (RAG) systems, a chatbot answers questions about a document that is normally meant for human consumption, such as a catalog or an article. The key lies in reliably matching the user's question to the relevant subset, or chunk, of the document, and then offering up that chunk to GPT with instructions to use it to answer the given question.
It can be helpful to use a more superficial analysis of the input, in context, to determine whether to even consult a document, and if so, which one. For example, a user query might result in an output such as,
-
Let me see. [rag-lookup HRHandbook]
which then results in a new input, typically from a vector database, such as
-
> [rag-result HRHandbook 0.4 Employees may...]
containing a source document id, a confidence, and the relevant chunk. A subsequent rule can make the final decision as to whether to use this source. If it fires, the chunk can be transformed into the final text using the GPT subsystem.
-
[rag-result HRHandbook (.*) (.*)] [where LessThan(?capture1,0.5)] → According to the employee handbook... [gpt rag {?capture2}]
prompt rag: System: Use the following text to answer the User's question. Text: {body}. User: {input}
More generally, a RAG prompt can be used any time you have some text that likely contains the answer to a question. For example the user may already be looking at a real-estate item from a property database, and they may ask "how many square feet". In this context, it makes sense to send that text directly to a GPT along with the question, leaving the retrieval of the actual detail as something the GPT is particularly good at.
Fallback to GPT
GPT is often used with some general instructions about the chatbot's role, the last turns in the dialog, and the user's current input, in order to predict a statistically likely output. This simple trick lets a GPT hold its own in a conversation, and has revolutionized chatbot systems. A comparison between the output of a traditional rule-based system and a GPT-based system is like night and day, with the GPT system apparently being able to deal with local context, anaphora, world knowledge, etc.
In fact, this success has lead to the wholesale abandonment of many of the "symbolic" natural language techniques introduced so far. But consider some underlying similarities between the two approaches.
- Each layer in a neural network is reminiscent of a series of classic if/then rules - weighing the evidence from the preceding layer and then locking onto one or more outputs.
- The multiple layers in a neural network work similarly to multi-step rewrite systems, where the output of one round of if-then rules becomes the input for the next round.
- Precisely one chain of rules can be said to have fired in order to produce a given output from the entire system
- Neural network attribution graphs show how useful intermediate representations can be associated with the activation of specific nodes in a trained network, and these groups could in principle be labeled, for simplicity, using predicates.
The key difference, of course, is that the rules in a GPT are inferred entirely from training data, rather than being programmed by humans. This in turn results in a scale advantage, in which billions of parameters can be used to predict an answer that is not only statistically likely in some superficial word-pair sense, but also in a deeper, semantic sense. This is what lets a GPT predict "Paris" to complete the sequence "The capital of France is...".
If a GPT works so well, then why not let it answer everything? Of course many systems do just that, but there are some practical problems associated with using pure GPT in a conversational system:
- The rules (i.e. connection weights) cannot be changed, at least not without a massive amount of data and training.
- As a result, specific behaviors can only be engineered by altering the prompt, which is largely a trial-and-error process.
- Responses take a large amount of CPU power to generate, making them slow and expensive to produce, especially when used for every response.
- Since each output contains some element of randomness, GPT responses can be hard to lock down with tests, and can decrease the effectiveness of caching.
So while many things that are hard with the symbolic approach are made easy with the connectionist approach, many things that are hard in the connectionist approach are also made easy by the symbolic approach! The Dialog API framework lets you use precise rules and strategies to produce outputs in a certain domain, while still being able to fall back to a general GPT approach to respond "in character" to things outside of that domain. For example a company representative chatbot can drive a conversation with accurate product and pricing information, while still being able to chat intelligently about things outside that domain, like the town in which the company is located.
Here is a combination of a fallback rule and a prompt rule that can serve as such a fallback:
-
* [fallback] → [gpt fallback]
prompt fallback System: You are an AI assistant named Michelle. Answer must be brief. {history 4} User: {input}
The Prompt should look something like this in the dashboard:
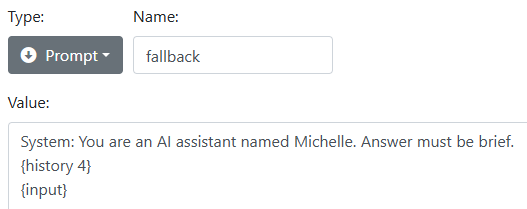
Remember that the prompt rule is a template. In this case it might expand to the command tag:
-
[gpt System: You are an AI assistant named Michelle. Answer must be brief.
Assistant: Hello! How can I be of assistance?
User: Where are you located?
Assistant: ACME is located in sunny Tuscon, Arizona.
User: what else is the city known for?]
Remember, this is the control output coming from the Dialog API, ready to be routed to a GPT. Prompts commonly use the headers "System:", "User:", and "Assistant:" to delineate the different roles. For this reason the {history} tag expands to multiple lines headed by "User:" and "Assistant:" rather than the more compact notation used by Dialog API.
You can think of the GPT as filling in gaps in the conversation. You can even use the GPT Fallback rule with Take Initiative if you are eager to get the conversation back on track.
-
* [fallback] → [gpt fallback] Moving on. [take initiative]
This might result in
-
> what else is the city known for?
Tuscon is home to some of the most beautiful hiking trails. Moving on. May I ask your name?
When a GPT subsystem is used, it will normally "patch" the [gpt] tag in the history with the actual GPT output. As a result, both the regular and GPT output are combined in the same transcript, and the two are indistinguishable. This also makes the GPT output available for regular Dialog API rules.
Examples and Tests
The Dialog API's dashboard contains features to document and continuously verify that your rules are working correctly. The first feature operates at the input pattern level, and can be specified within the rule itself with the Examples checkbox.
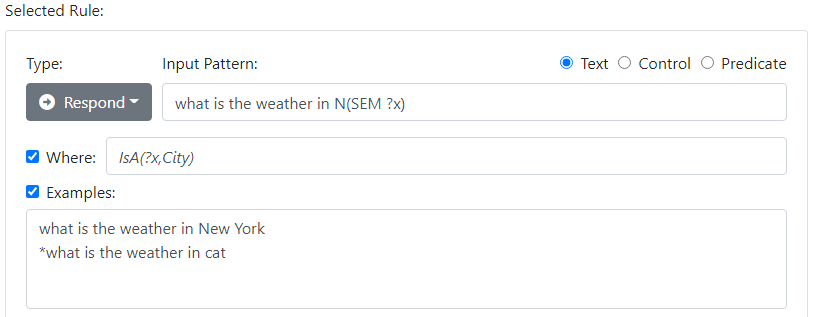
Examples let you specify a list of sentences, some of which should match the pattern, and some of which should not. Following a common practice in linguistics, examples that should NOT match the pattern are prefixed with a '*'. If any example fails (that is, a positive example does NOT match, or a negative example DOES match), then an alert appears.

You can then compare to a proposed version of the examples that places or removes '*' characters in a manner that would allow all examples to pass. You could adopt this suggested replacement, or you might examine your pattern to identify any problems.
You can also add Tests. A Test is a complete series of inputs and outputs that exercise certain rules. Typically the Model Tester is used to probe rules while they are under development. Often you will come up with a scenario that you want to "lock down" with a Test, that is, you want to be alerted if subsequent changes cause the scenario to fail.
To do so, you can add a Test item, typically close to the rules that the Test will exercise. The Test contains a Transcript, which you will often copy directly from the History section of the Model Tester. If a test depends on certain World predicates, then you should add them to the Initial World section. Tests are especially useful for documenting and verifying expectations around World predicates. If the rules exercised alter the World, then you would document this by updating the Final World section.
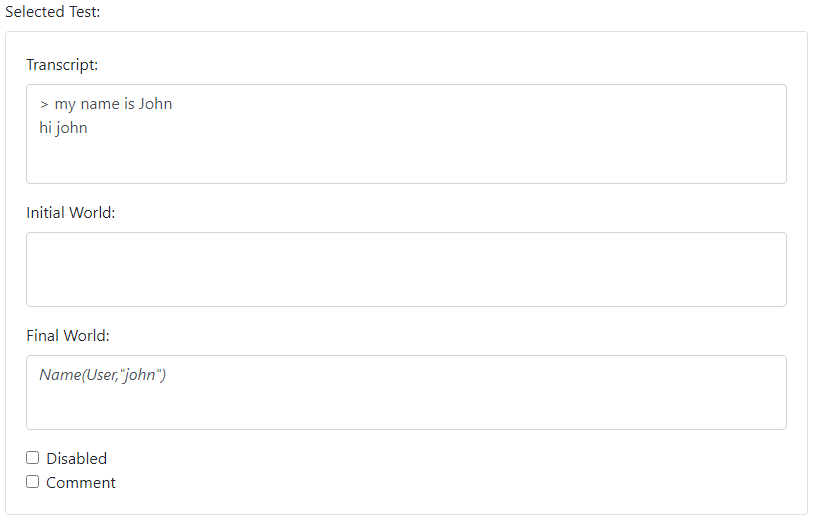
Tests are easy to create, and fill an important role in preventing regressions in functionality as you add more rules to your system. Tests work best when they are simple, and focus on documenting a single, well-defined behavior.
Examples and Tests are used during rule development, and are ignored when your mind is running in Production.
Dependent Models and Stock Models
Rules are organized into Models. Often it makes sense to organize rules with a similar purpose in the same model. For example you might have a model that specializes in reducing sentences to canonical form. When you are working with a model, it is easiest if you can test that model in isolation. However this is not always possible, since your model may rely on rules from another "dependent" model. The Dependencies tab lets you add dependent models. It is similar to the Mind editor, because you are essentially specifying the minimal "mind" (i.e. collection of models) that allow your model to be tested. These dependencies are used when testing your model in the Model Tester, as well as for running all Examples and Tests in the model. When a model has dependent models, tests within that model also serve to lock down expected behaviors of the dependent models.
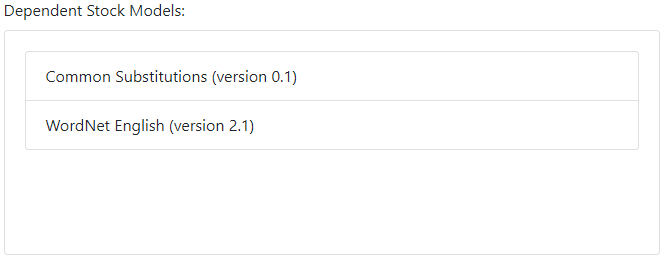
There are also a few "Stock Models" that are available to all ChatBot developers. For example, the "Common Substitutions" stock model contains many useful substitutions, such as converting "can't" and "cannot" to "can not". (Other, more specialized stock models can also be mounted on your account - please inquire for details.) Naturally, stock models will often appear as dependencies for a model.
WordNet
One commonly-used Stock model is WordNet, a widely-used resource in Linguistics developed by researchers at Princeton University. By using WordNet, you gain access to a dictionary of English words, their senses, and an ontology.
If your model has WordNet as a dependency, then you will find a WordNet button next to the rule panel that lets you quickly lookup any word. For example, here we lookup the word "german":
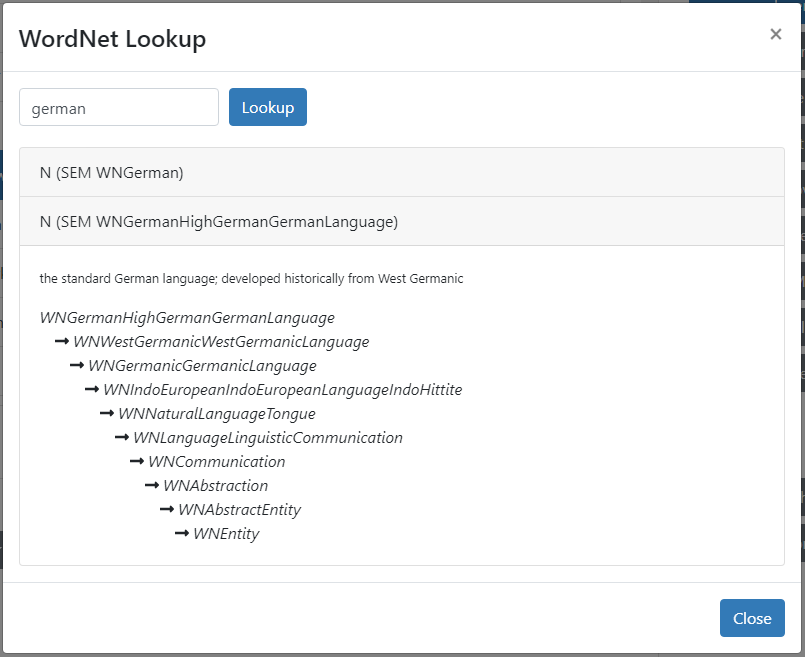
There are two senses for "german". You can see from the definition, or "gloss", that the first is for a "person of german nationality", and the second is for "german, the language". Note that all WordNet predicates use the prefix "WN". The ontology shows us, among other things, that
-
IsA(WNGerman,WNNaturalLanguageTongue)
This seems to be a useful "level" of generality. Indeed, looking up "swahili", we also see that IsA(WNSwahili,WNNaturalLanguageTongue).
This suggests a rule such as:
-
do you speak N(SEM ?x) [where IsA(?x,WNNaturalLanguageTongue)] → I speak English.
or simply:
-
do you speak N(SEM WNNaturalLanguageTongue) → I speak English.
This matches "Do you speak English", "Do you speak German", "Do you speak Swahili", and most other languages you can think of.
Note that all senses of the word are processed in parallel, so the sense of the word "german" as a type of person would simply not satisfy this rule, but it could, of course, satisfy some other rule, such as:
-
I met a N(SEM ?x) the other day [where IsA(?x,WNPersonIndividualSomeoneSomebodyMortalSoul)] → Oh. What did they say?
It's important to note that WordNet is used only for words that don't match any Lexicon rules in your own models. This lets you build specific knowledge around certain entities that your chatbot is familiar with, say, your company and your products, while using WordNet to get a general idea of what a user is talking about and react appropriately.
Wrapping Up
We look forward to seeing what you build with the Dialog API. As you experiment, please keep our solution development services in mind. With over a decade of experience building chat solutions, we are ready to assist your team with technical expertise, custom models, and more.
Please send questions and comments to sales@mediasemantics.com.